
This chapter will discuss the testing approaches mentioned in the previous article: “What is ETL”. We will try to examine the tests using database solutions. In other words, we will exemplify an ETL testing approach. Knowledge of the architecture of the query-writing tools will be of much help here (databases in Microsoft technologies will be discussed) – we will learn how to find the code needed to identify a system view or data-transforming procedures.
We will bring the topic of system views closer, in which testers can very often find lots of information about the database architecture. We will also learn operations on logical sets allowing us to operate on data holistically. We will try to attach all the items described above to the specific ETL testing approaches.
ETL Testing Tools – SQL Server Management Studio
SSMS (SQL Server Management Studio) is a tool that allows us to execute operations on databases. This tool has many equivalents, like Oracle SQL Developer, but their high-level workflows are vastly similar.
In this chapter, we will deliberate the notion of structural testing where the code’s correctness is verified, e.g., data are loaded from the source to the target database only by data-loading procedures. In this case, we can check how the whole process works by writing instructions per the specifications, or we can investigate the procedure’s source code and verify if it runs properly.
Therefore, to check the procedure’s source code, we must connect with the tool mentioned previously. Then, we connect with the correct instance and database needed for our tests, and thanks to the Object Explorer tool, we have access to the whole database architecture.
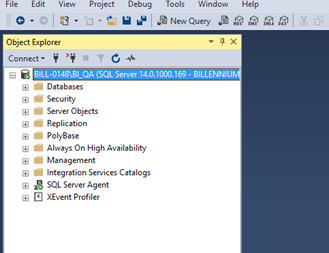
As we can see, the tool gives us insight into all the objects of the given server, starting with databases and ending with information in a specific table column. However, let us return to the structural testing based on, e.g., checking a procedure and looking into its code.
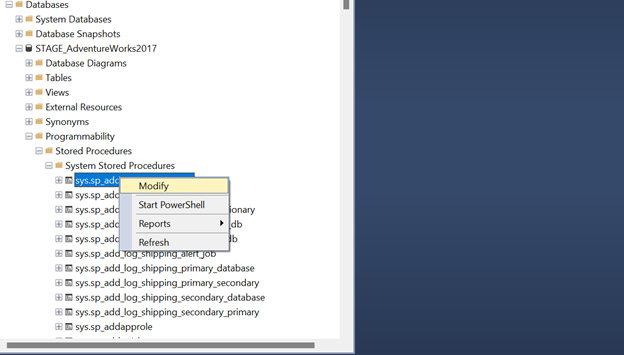
Enter the database via the Object Explore tool. Next, enter ‘programmability’ and then choose ‘Stored Procedures.’ Look for the procedure to verify, then right-click on it and click Modify.
Here we can see the code of the procedure:
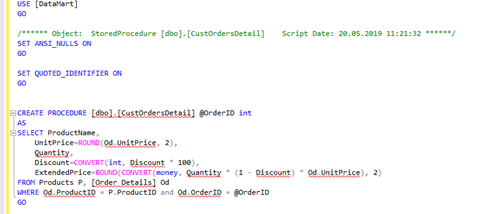
Now, the procedure can be carefully analyzed, and we can see the source and target tables for the existing transformations. However, we must be highly cautious when examining the code as it must stay intact! Any queries inside the syntax can be copied and run in a separate window to see if data about to be loaded were correctly retrieved, etc. However, do not run the procedure – this method is used only in the context of code analysis.
ETL Testing – Sets and Logic
This subchapter will discuss the logic behind the sets and how they work. This type of link is often used to compare data in the target-source categories or between the steps of the ETL process concerning the rules explained above.
The methods of joining tables using the FROM clause described in Chapter 1 concern combining sets horizontally. These methods were types of joins (INNER, OUTER JOIN) and the rules for matching records that appear before the ON operator. The outcome was a set of elements described by all columns (attributes) from the joined tables. This is why we call them horizontal.
The second group of operations performed on sets are vertical operations:
- UNION – summing the sets
- EXCEPT – removing the sets
- INTERSECT – the product (standard part).
They always operate on the results of all queries (entry tables) and return a result table, a set defined precisely like the first entry table (number and names of the columns). However, they contain elements (rows), which derive from the sets arithmetic defined by UNION, UNION ALL, EXCEPT, or INTERSECT operators.
ETL testing – conditions to perform multiple operations
Multiple operations can be performed in one query. To do so, certain conditions must be met. The primary rule of any vertical set operations is that all entry tables must have a similar structure. The number of columns in every set (query) must be identical, and the data types of each column must match each other. The column names do not matter. The attributes will be named in the result set, just like in the first query.
An additional condition stems from the definition of the sets and the operations performed on them. The elements inside the set are not organized. Therefore, the operations on the sets always work on the disordered elements. Ordering greatly impacts efficiency and, based on what we have just explained, does not influence the results. That is why we cannot use the ORDER BY operator in the queries applied to join/remove or determine the common parts of the sets.
The ORDER BY operator can be added at the end. Then, it will refer to the result table – the result of all defined operations on the sets.
Here, we will discuss and explain each of the logical operators:
- UNION operator – joining sets.
UNION is a sum of sets. As a result, we will obtain the elements from the first and second sets. In theory, the UNION DISTINCT operation removes duplicates. Mainly, it concerns the duplicates of common parts of the sets and those in the entry tables.
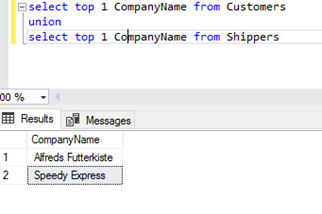
Each query that participates in joining sets returns duplicated values. We do not remove them with DISTINCT, but with the UNION operator, we obtain unique values for the (A + B) set. They are removed from the entry queries and the common parts of sets A and B.
- The UNION ALL operator – joining without duplicates removed.
The second method of joining sets is UNION ALL – no duplicates are removed. This time, we will take the first ten rows (using the TOP 10 clause), and even though the results are copied, the result returns twenty rows.
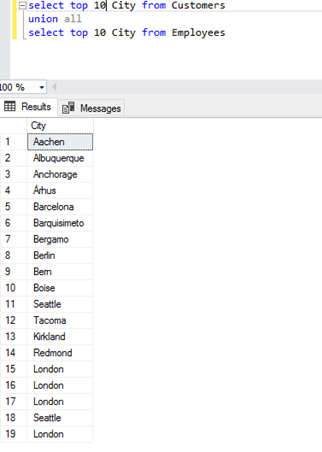
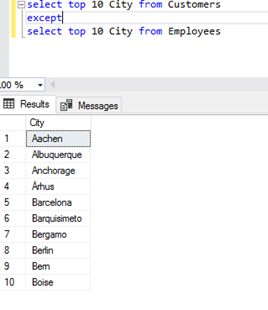
- The EXCEPT operator – removing sets.
The rule is simple: all the elements shared with the second set (the result table, the query on the right side of the EXCEPT operator) are removed from the first set (the left side of the EXCEPT operator).
Removing sets with the EXCEPT operator is implemented in SQL Server only as EXCEPT DISTINCT – all the duplicates are removed from the result set.
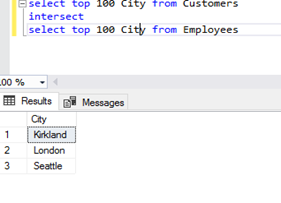
- INTERSECT – common elements of the sets.
The INTERSECT operator is used to find common elements of the sets. Like with EXCEPT, SQL Server has implemented INTERSECT DISTINCT – common elements with no duplicates.
The order of operations:
We can work on multiple sets within one query and use various operations. It is compulsory to keep the order of operations – just like in mathematics.
System Views in ETL Testing
This section will cover the subject of the system tables (views). If read correctly, the views can give us information about the database structure and its objects. Thanks to these tables, we can check, e.g., if the database columns have the right data type and correct default values (according to the requirements) – if they do, are their values implemented, or do the tables have correctly described relations (as we can see the primary and foreign keys). There are many possibilities, depending on the tests we want to carry out.
We will discuss a few of the most helpful system views that testers can use more frequently than other views.
ETL Testing – types of views
There are two approaches to the system views in SSMS. These are sys.views – a line of views that allow us to read structural information like sys.objects or sys.tables that provide information on objects or tables, respectively. In many instances, using these views means joining on object IDs, which can be burdensome as their connection must be searched. We, however, are going to focus on the INFORMATION_SCHEMA views.
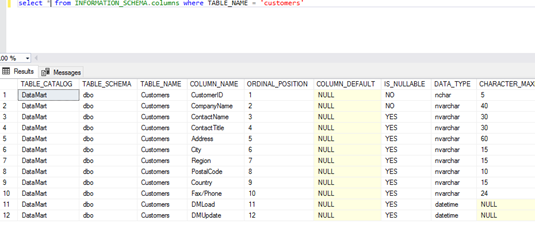
The first and most frequently used view in the ETL testing is INFORMATION_SCHEMA.COLUMNS. Every view is created with a standard SQL query.
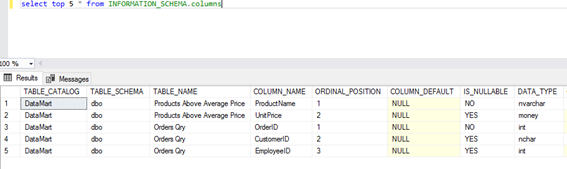
As we can see, the columns in this view provide the information on the table schema, table columns, the table itself, and information about the columns, like:
- If the column is nullable (whether NULL values are accepted or not)
- If there are defined default values
- The column type (numeric, date/time, character/string, etc.)
- The column size (a character/string type)
- The column precision (for the ones of the numeric type)
and other helpful information.
The queries and views can be made with any conditions and aggregations. They are called system views, as data inside them cannot be changed. The queries, however, can be built by the needs of a test.
Another system view worth mentioning is INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE. This view contains information on the relations (keys) within the tables.
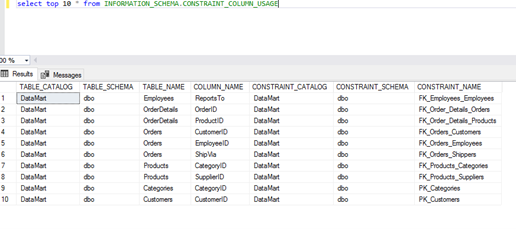
The information contained within the columns are:
- Database
- Table schema
- Table name
- Column names
- Constraints put on the columns (keys).
This view can be used to check the relations among the tables or to see if each table has the primary key.
The third view used in tests based on the data structure is INFORMATION_SCHEMA.VIEW_TABLE_USAGE.
Quite often, the last stage of working on a database is to provide ordered data for the report dedicated to the end user. In such an instance, verifying if the view gets data from the right tables is best. This system table can be used for such a test.
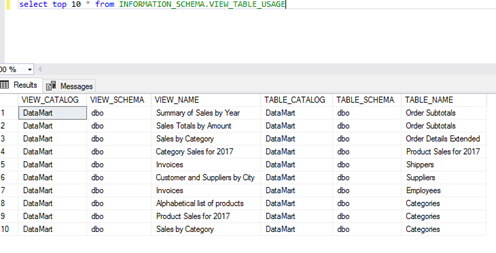
The information in this table gives us knowledge of the database, view schema, and tables from which the view draws data.
Summing up, many other views keep different kinds of data. The opinions we use for our tests depend on what we want to obtain and what we think would work best.
Linked Server
This subchapter covers working (ETL testing) with data when verifying transformations or checking the target-source loading process – when both phases are not correlated. Let us imagine a situation where the developer possesses specific ETL testing tools (e.g., IPC or SSIS), and the tester can only see the source and target databases, which exist on entirely different, unrelated servers.
The method discussed in this subchapter means intervening in the database (both source and target databases), and the tester can rarely act in such a way. In this case, we will assume that the developer gives the tester a free way to their actions.
Returning to testing, databases and servers where the databases exist are not correlated – only the developer can join them using an ETL testing tool. In such a situation, the tester’s possibilities for testing are limited. The solution to this problem may be creating linked servers (the linked server is named db_link in Oracle). This action means creating a link between two servers, allowing us to create queries and perform actions between them.
A question may arise: why do the developers need ETL testing tools if a method like this exists? Here, purely optimization issues are the case, as linked_server tends to be inefficient. Therefore, we can only run queries in unlinked servers and databases if those queries are reasonably small. Transformations would be unsuitable for this kind of operation.
We can use GUI or system views to check what servers are defined within our current server. From the Management Studio level, all that is needed is to unfold the Server Object folder and then Linked Servers. Here, we should see the linked servers if we define them. In addition, there is also the Provider subfolder where we can find all the installed drivers that can be used for linking within the linked server.
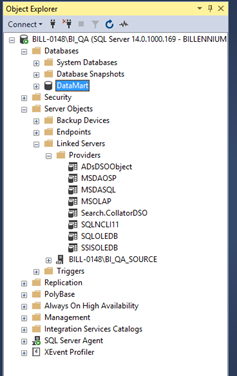
There is also the sys.servers system view at our disposal, which contains the data we need. We add a new linked server by right-clicking on Linked Server, and then we choose New Linked Server from the context menu – the following window should be displayed:
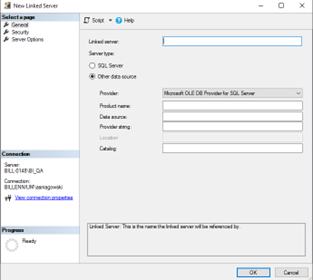
We provide the name of the object created as the Linked Server – it is crucial to choose a well-thought name as the name will be used in our queries, and it will not be possible to change it later. When we connect to SQL Server, we choose SQL Server as the server type. At this point, the name of the linked server must be the name of the server we are trying to connect to.
After completing the general information, go to the Security tab:
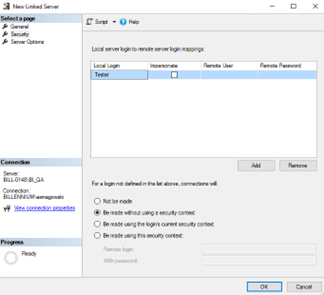
In the upper part, we can map the login on our current server to the login on the linked server. In many instances, however, it is not possible to configure login mappings. Then, we can define connections for all logins that are not visible on the list by selecting the options in the lower part of the window. At this point, we usually see an SQL Server account dedicated to this kind of connection.
After everything is settled, we click the OK button – the connection should be established. There should be a server with existing databases displayed in our GUI.
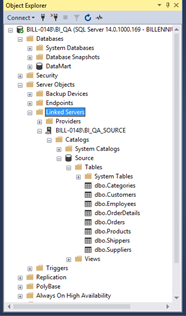
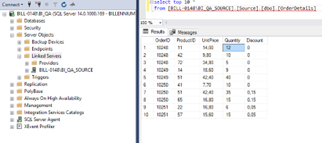
After performing this operation, we can test data between various servers.
ETL Testing – empowering data-driven decisions
ETL testing is at the forefront of ensuring data integrity in today’s data-driven business landscape. As companies increasingly rely on extensive data sets to make critical decisions, the extract, transform, and load (ETL) process is becoming one of the essential foundations for reliable analysis.
This article delves into ETL testing, showing how it acts as a gatekeeper to data quality, preventing costly mistakes and misguided strategies. From using powerful ETL testing tools, such as SQL Server Management Studio, to applying advanced techniques, such as set operations, ETL testing enables organizations to transform raw data into useful information.
Through these practices, companies can improve data flows and gain a competitive advantage through more reliable business analytics. In an era where data is paramount, robust ETL testing is the underrated hero of any successful data-driven initiative.
So, if you need experts on ETL, extracting valuable insights from your data and testing it to bring you the most measurable results, contact us to discuss your goals.
















