
In today’s data-driven world, ETL (Extract, Transform, Load) processes play a crucial role in processing data from various sources. ETL process testing is essential to ensure the integrity, quality, and reliability of the processed records. AWS offers a wide range of tools to support the execution of these tests.
This article will discuss how to perform ETL testing in AWS, using SQL queries in Amazon Athena and PySpark as examples.
ETL in AWS
AWS offers a range of services for building ETL processes, such as:
- Amazon S3 – a storage layer capable of holding unlimited amounts of data,
- AWS Glue – an ETL orchestrator that enables data preparation and loading for analysis,
- Amazon Athena – a serverless data analysis service that allows SQL queries directly on data stored in S3,
- Amazon EMR – a service for processing large-scale data (Big Data), supporting tools like PySpark,
- Amazon Redshift – a data warehouse service optimized for advanced analytics on large datasets.
Why ETL testing is necessary
ETL processes often operate on large volumes of data, and errors can result in:
1. Data loss.
2. Poor data quality.
3. Incorrect analysis outcomes lead to flawed business decisions.
4. Integrity violations.
ETL testing consists of the following phases:
- Source Data Testing: verifying aspects such as data formats, missing or empty values, and duplicates.
- Transformation Testing: ensuring the correctness of business rules and transformation logic based on provided Source to Target Mapping (STTM).
- Target Data Testing: Checking if the results meet expectations, i.e., whether only the required data has been loaded, and whether the data has been placed in the correct tables and columns.
ETL Testing Using Amazon Athena or PySpark
Amazon Athena allows for running SQL queries on data stored in Amazon S3. This makes it an excellent tool for testing at various stages of the ETL process. On the other hand, PySpark enables distributed data processing, which is particularly effective for testing large data volumes.
ETL Testing Steps
Before starting the tests
1. Review the requirements, documents, and data mappings to understand the scope and specifics of the ETL process. Based on this analysis, prepare the necessary test scripts and queries.
2. Preparing test data:
- Amazon Athena: confirm with the development team that all test data is loaded into Amazon S3 in the correct structure (e.g., file formats: CSV, Parquet).
- PySpark in PowerShell: Load the input data into temporary test tables for further testing.
Scope of Testing
1. Input data testing
check the correctness of input data:
• data format (e.g., file formats such as CSV),
• location and naming of files/ tables,
• number of columns,
• data types,
• data integrity (e.g., no null values in required fields).
2. Testing output data after transformations
run SQL queries or automated scripts to verify data after transformations:
• Check and compare the number of records on the input and output sides: ensure that the number of records remains the same on both sides unless a justified change occurs (e.g., removal of duplicates).
• Identify which records were lost or ignored during the ETL process: verify that this aligns with the business logic and transformation rules.
• Compare data between input and output: use queries with the EXCEPT operator to compare data. Depending on the layer, this comparison could be 1:1 or based on business rules (transformations) described in the mappings. This may include tests for: data format conversions, splitting a column into multiple columns, joining data from several tables, extracting specific values based on business rules (e.g., CASE WHEN statements).
• Check primary keys to detect duplicate records: ensure there are no duplicates unless the business logic allows for them.
• Check for empty values (null) in primary keys and business keys (as listed in the mapping).
ETL Testing in AWS – How to run scripts
Athena
1. From the Analytics section, select the Athena service.
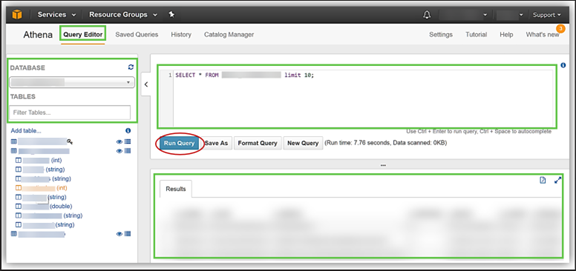
2. In the Query Editor window, verify that the correct database is selected from the dropdown in the top-left corner.
3. In the editor field, enter your SQL queries and run them.
4. Analyze the returned results, which will be displayed directly in the console.
If you want to download the results, click the Download Results button.
PySpark
1. Run PySpark in PowerShell: command pyspark.
2. Load the test data into temporary tables: command spark.read.option.
This command needs to be prepared with the schema:
spark.read.option(“header”,””).(”).registerTempTable(”)
where
OPTION = true – if file has got headers or false – if file hasn’t got headers
FILE_TYPE = csv – if we have path to file with .csv/ .dat or parquet – if we have path only to pt_file_id
SF_PATH – path to files which we will check
TABLE_NAME – table names which we will use in our queries

3. Enter the SQL queries and execute them.

4. Analyze the returned results that are visible directly in the console.
Best Practices for ETL Testing in AWS
1. Automation: scripts that verify data across different sources, taking into account the transformations that occur. Automated tests help ensure data integrity and consistency throughout the ETL pipeline.
2. Documentation: detailed mappings that include all transformations applied. This documentation should also cover functional and non-functional requirements, ensuring clear expectations for the ETL process.
3. Data Validation at Every Stage: ensuring that data at each layer of the pipeline meets expectations. This includes validating data after extraction, transformation, and loading, to verify that all processes are working correctly, and the data is accurate at each stage.
ETL Testing in AWS – Summary
Amazon Athena and PySpark are quite recognizable and frequently used tools for testing ETL processes in AWS. Athena is useful when we want to quickly examine data using SQL queries, while PySpark is employed for validating more complex transformations on large datasets. The appropriate choice of tools should be based on the volume of test data, the complexity of the transformations, as well as project resources and defined timelines.
Article written by Magdalena Roszewska & Magdalena Rakowska – Test Lead Technical Leaders at Billennium.















