

In this article, I want to share some brief details about Batch Processing and how to process messages as a batch in MuleSoft.
Batch Processing:
Batch processing handles large amounts of data. It can process data quickly, minimize or eliminate the need for user interaction, and improve the efficiency of job processing. In MuleSoft when we need to interact with or process large amounts of data or process messages as a batch we can use Batch Processing, which can be achieved by batch scope.
Batch scope in the mule application has multiple phases in which it divides the input payload into individual records, performs actions on these individual records, and then sends the processed data to target systems.
Batch job is an asynchronous process. It works asynchronously with respect to the main flow or calling flow.
Each batch job contains three different phases:
Load and Dispatch:
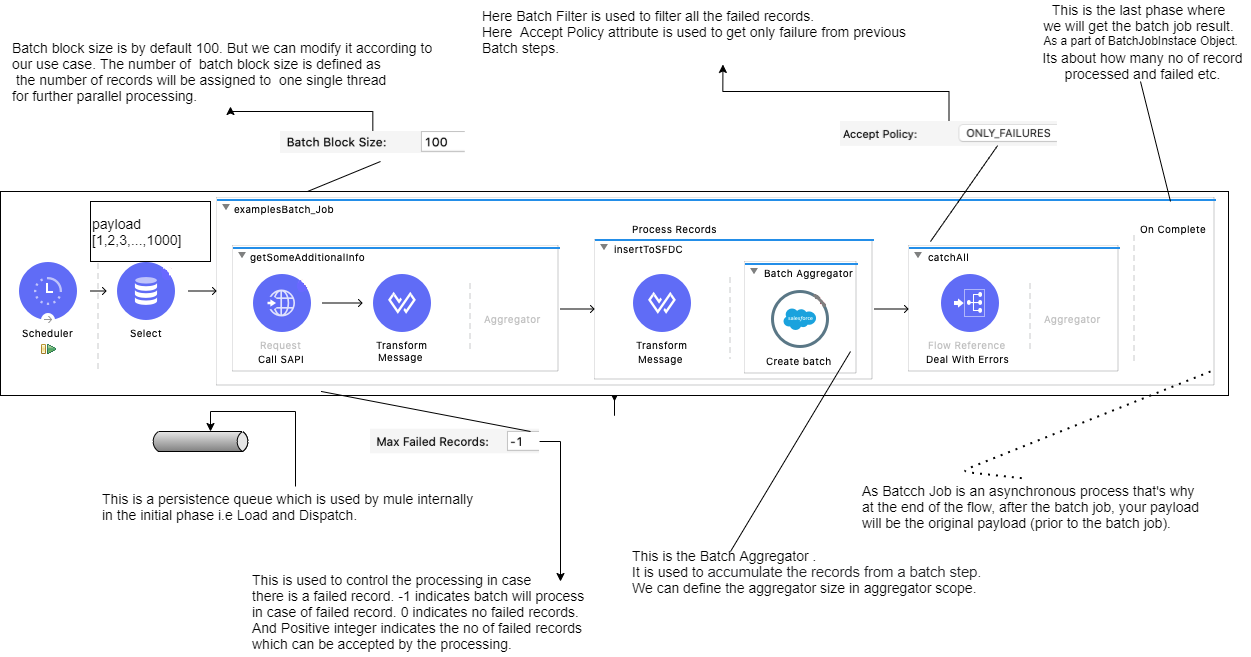
This phase will create batch job instances, convert payload into a collection of records and then split the collection into individual records using Data weave (internal) for processing. In this phase, Mule internally uses a persistence queue for processing and storing records.
Process:
In this phase, Mule starts pulling records from the queue as per the configured batch block size. Next, Mule sends the records to their corresponding batch step and processes them asynchronously. Each batch step starts processing multiple record blocks in parallel. However, batch steps process the records inside each block sequentially. After processing all records it sends those records back to the queue, from where the records can be processed by the next batch step.
On Complete:
The last and optional phase to create a report or summary of the records it processed for the particular batch job instance. It will tell us how many records were processed, and how many failed.
Batch Components:
Batch Step:
The batch step is generally a part of the processing phase. After load and dispatch, the batch job sends all records to the batch step. During the batch step, the batch performs work on each record. We can apply filters by adding Accept Expressions within each batch step.
Batch Aggregator:
The batch aggregator scope only exists in batch steps. The batch aggregator scope is used to accumulate the records from a batch step, and send them to an external source or service in bulk. The batch aggregator performs on the payload, not variables.
There are two types of batch aggregators: Default, where we can define the size of the aggregator, and Streaming, where we can use the aggregator to stream all the records and process them, no matter how large they are.
Batch Filters:
The batch filter can only exist in batch steps. We can apply one or more filters as attributes to any number of batch steps. There are two available attributes to filter the records.
- Accept Expressions :
– The Accept Expression attribute is used to process only records that evaluate to true or satisfy the expression. - Accept Policy:
– The Accept Policy has 3 default attributes used to filter the records.
NO FAILURES: The batch step processes only those records that succeeded in previous steps.
ONLY FAILURES: The batch step processes only those records that failed to process in previous steps.
ALL: The batch step processes all records, regardless of whether they failed or not in previous steps.
Flow Diagram of Batch Processing:
Note:
- The Batch Job is generally used when there is a large number of records that need to be processed in parallel.
- The Batch Job’s Batch Block Size is defined as each thread will only take that number of records and process it.
- The Batch Job’s Aggregator size is defined as that number of records will be accumulates and processed to the external system in bulk. It is used when we need to process fixed amount of records.
- In Batch Failed, records can be handled by the batch filter. We can also control the flow processing by using the Max failed record field by providing an integer value.
- The Batch job uses 16 threads at a time to process the records and each thread is assigned a given number of records as defined by the Batch Block size.
- The Batch job performs an implicit split operation on the Mule message that recognizes any Java, as well as JSON and XML payloads. It cannot split any other data formats.
Reference link:














