

In this article, I want to share with you our solutions to the 10MB limit problem in publishing Payloads in Mule 4. We checked several solutions, each has its advantages and disadvantages, which you will learn about in this article. I hope that the following analysis will be helpful for you.
Intended Audience: MuleSoft developers/Architects who are struggling to find a way to overcome this limit in the easiest way.
Problem
As Mentioned over MuleSoft Documentation (https://docs.mulesoft.com/mq/mq-faq), we can only publish messages till the size of 10 MB and if the size is greater than this we will get the following exception (Payload_too_large).
This limit is quite challenging during times when we have NFR (Non-Functional Requirement) stating that payload size can be greater than 10MB.
Solution (1)
As stated over documentation.
The first solution is to split the payload into chunks based on some logic and assign an ID to each and publish it to Anypoint MQ. At the receiver, apply the logic to aggregate the messages and then carry forward the business logic.
This approach has few shortcomings as stated below:
- It requires extra logic to assign groupID, sequenceID to each message while splitting,
- Queue has to be FIFO so as to maintain sequence and note that FIFO queue has tps limit of 300,
- Due to any error if publishing chunks becomes out of order then aggregating will be too difficult.
Solution (2)
As stated in the documentation.
The second solution was to implement a claim check style service in which you store the payload in a file system or blob storage, and then put a pointer to the payload in the message so it can be downloaded later. However, you must manage access control to the blob storage for both the sender and receiver. The above solution involves extra resources (external file system or blob), logic and is not quite straight forward to implement.
Solution (3)
After following up with Mulesoft for a better solution, below was the suggested. At the producer end compress the message using G-Zip Connector followed by encoding using a base-64 function in DWL and then publish. Similarly, at the consumer end decode using base-64 function followed by G-Zip decompression.
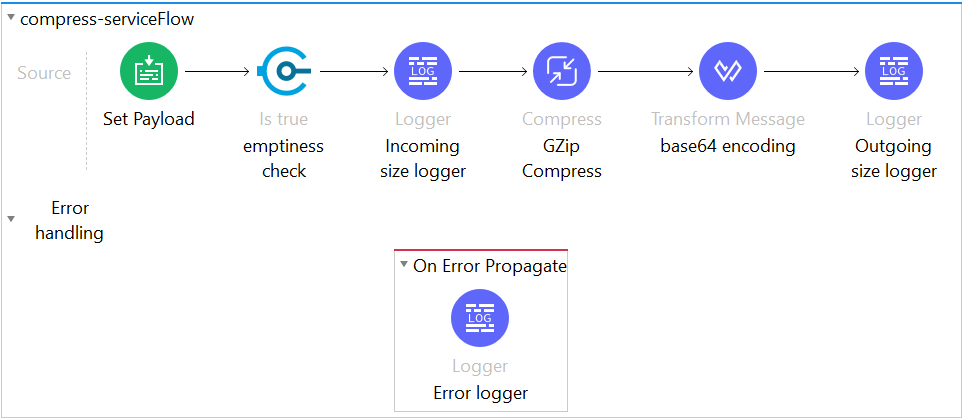
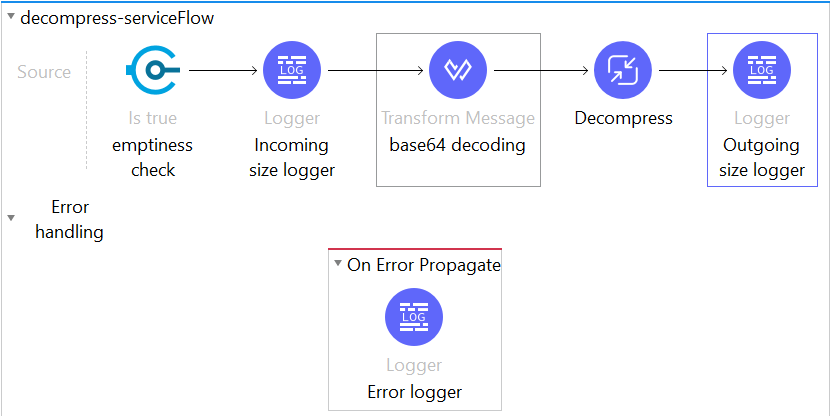
The bulkier the payload (also depends on data redundancy) the greater is the compression ratio achieved. Besides publishing to AMQ, this can also be used to compress payload before making HTTP calls to reduce bandwidth usage while transferring and improve performance especially in Mule API to Mule API calls.
Notes: This can also be used for non-mule APIs provided they can decode the Gzip data. Compression/Decompression using G-zip is also used extensively in improving website performance.
Note: Compression/Decompression uses CPU_INTENSIVE thread pool.
For testing purpose, I tried to process files of varying payload till 70MB, after compression payload size got reduced in the range 2-8 MB which can be easily published to AMQ.I have tried different MIME types of data like application/JSON, application/XML, text/plain, multipart/form-data, application/CSV, binary file, etc and all these worked successfully. Also, after decompression, the payload will be coming as MIME */* so you need to use the read function of DWL to map the correct MIME for processing ahead.
e.g
%dw 2.0
Output application/json
—
read(payload,”application/json”)
Solution (1) requires extra split and aggregate logic in order to be built. Solution (2) requires extra resources, such as external file system or blob. Additionally, logic is not that easy to implement. Taking all of it into account, in my opinion solution (3) is the best and the easiest of all to implement. And that’s why I recommend it.
As you can see, this process is not easy but it will certainly streamline and simplify your operations.
Reference links:














