

This isn’t an article that provides solutions; rather, it highlights the problems to raise awareness. Occasionally, I’ll link to other resources with potential ideas for improvement. My goal is to emphasize the numerous challenges we face when working in teams within a non-technical context.
I’ve seen countless posts, articles, and videos about project failures blamed on the technologies chosen. Of course, this happens all the time. Someone selects a cloud provider and ends up burning $100,000 on a simple to-do app (yes, I’m exaggerating here), or someone opts for a shiny, modern frontend framework that’s “blazingly fast”—only to waste two days implementing a modal. We’ve all been there…
The truth is, you can’t predict the future of technology, its inevitable changes, or its long-term stability. What you can do is focus on the present, work with today’s facts, and make informed decisions grounded in reality.
That’s about technology, but in my opinion, it’s people’s behavior—not the tech stack—that causes most projects to fail. I can’t understand why only a small group of people recognizes this. Factors such as:
- Ego
- Mismatched teams
- Ineffective communication
- Micromanagement
- Unclear roles and vague responsibilities
- Wasted time in meetings
…and countless other issues
are the real culprits behind wasted time & money.
The best way to bring you to my side is by sharing situations I’ve gathered, witnessed, or heard about during work or consultations. I hope the sheer quantity of these examples will serve as a strong enough argument to confirm the title’s thesis.
Intrigued? Let’s ride through the topic.
PS: This article is inspired by the saying “a drop scrapes the rock,” which also applies to working in IT. Many small things can cause the collapse of even the best projects.
Code Review Culture
To investigate problems in a project, I suggest starting with how the code review process works. I’ve identified three common types:
- Normal (everything’s fine)
- Fighting Arena (constant arguments and ego clashes)
- 0 Comments (everything is blindly approved with an LGTM)
If your project’s code review process resembles the image below, it’s definitely a red flag.
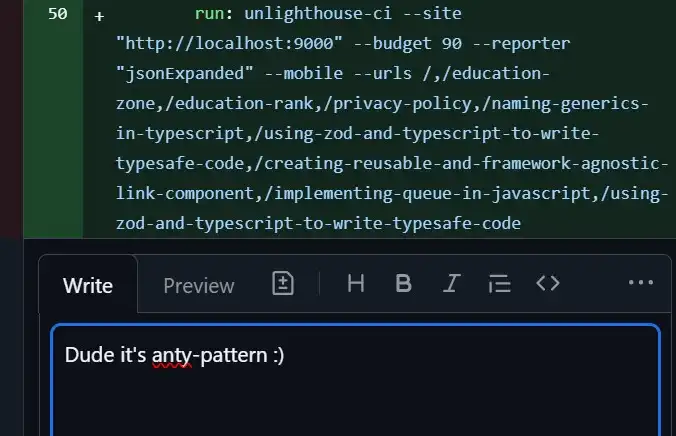
Going to either extreme — like in politics — is unhealthy. The code review process should provide value to both the author of the pull request and the reviewers. It’s an opportunity for everyone to learn from one another and to safeguard the application from potential issues that might arise if bad code reaches production.
We need to understand that every message we write requires a context switch and a reply. It wastes both your and your teammate’s time if the question or message doesn’t make sense. Often, developers who “think they’re better” prefer to showcase this during code reviews. I’ve seen this countless times.
It can be easily fixed by applying pull request conventions, as mentioned in the Improve code reviews in the 10 steps article.
Ok, we’ve covered the problem connected with fights in code review, but what about situations where nobody cares? Everyone just says LGTM? Yeah, I’m sure you’ve seen these guys too. Whatever you put in the code, they’ll accept it. I suggest a little experiment: put random stuff in the code and see if they’ll accept it. Let’s say the following code:
const joshIsClown = true;
console.log(`Echo`, process.env.SECRET);
Maybe it’s a bit much, but to summarize this section: people may just slown down the progress with 0 value added, if instead of productive discussion they’re playing in “I know better” game.
Poor Communication Problem
Let me highlight the context first. Everyone has been working hard on features for at least 3 months, and then comes the day you want to ship it to prod. The testers begin verifying everything your team has tried to connect. There are bugs, defects, and generally issues. They start raising them. Then, you see the following messages:
Tom: Hi, what's up bro, do you have 15 minutes for a quick call?
Tom: Are you here?
Harry: Hi, yeah, how can I help you?
// 4 hours later
Tom: Hi, are you here?
If you’re reading this, you’ve already experienced a context switch, just like in the first heading. First, you read the message. Then, after an hour of waiting and wondering what he meant, you find yourself repeatedly checking it — maybe the notifications aren’t working, who knows.
This can happen so often in bigger teams that it becomes frustrating. Communication needs to be straight to the point, especially when you’re working under pressure. If there’s a “lighter” time, you can write however you prefer (it’s not about being Optimus Prime), but the communication aspect is super important — it just saves time.
Poorly Described Work
Have you ever seen tickets like that?
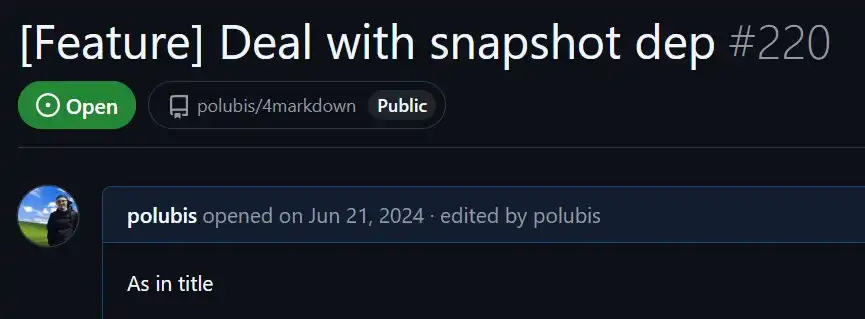
Many projects have such tickets. If you’ve come across well-described work, consider yourself lucky. Honestly, many teams don’t invest time in properly detailing their tasks. This is a mistake because, later on, everyone has to ask others for clarification on what needs to be done or how things should work, leading to yet another context switch.
Laziness in this area, or assuming it’s unnecessary, will cause a cascade of problems. Maybe not now, but in the future. Imagine these scenarios:
- Josh has a heart attack — he knew what needed to be done (he talked to the client), but now only the client knows.
- The tester found a bug in a new code, but the ticket is blank, and no one knows if it’s a bug or a feature.
- The developer (because the ticket was vague and empty) changed 100 files for refactoring — because the ticket was too general and said nothing, so they changed what they preferred.
I picked three examples, but there are countless more problems that can arise from this. How can you deliver quality work if you don’t even know what quality looks like? In this case, it becomes a matter of personal preference rather than a clear standard — and, in the worst scenario, those preferences will change depending on who’s working on or testing the task.
Ego Over Benefits
Ego in IT is a huge problem. The industry is dominated by males… In software craftsmanship, there are endless ways to implement a given feature. The factors that determine which idea to choose should be purely empirical.
However, if you have two developers at the same position/level on the team, and if their character traits include this “magic” piece, you can be sure they will bottleneck progress. Instead of selecting a problem, creating a PoC, planning, and picking the best solution, they will fight each other and try to force their own approach.
It’s toxic… People change very rarely. It’s like doing something with your dad, and he is always complaining about something unimportant, not accepting your work. “You’re holding the hammer wrong,” “You’re cutting the flowers incorrectly,” “Please learn how to hold the desk while I’m drilling,” and so on.
Blurred Responsibilities
Take a look at governments. If there is no person responsible for something concrete, you cannot understand why certain attempts fail. The same applies to projects. If there is, let’s say, a release manager, he should be responsible for maintaining and scheduling the entire release process. Everything around this topic, and if it fails, should be fixed in his area (I’m talking about process-related problems, not bugs or defects introduced by developers).
Toxic blaming culture is something you need to avoid, but no-blame (the opposite) is simply toxic. You cannot avoid saying why certain things happen.
Another situation arises when a developer constantly delays progress because they are introducing bugs into the code. This should be pointed out in meetings (of course, said nicely). There’s no need to be cocky or toxic, but it needs to be highlighted. Skipping pointing out such problems leads to frustration among other team members. We should localize problems in our work and solve them without unnecessary emotions.
“If during meetings or discussions about certain topics at work there are emotions, you’re probably doing something wrong…”
I’m not saying you should always be finger-pointing at specific people. If it happens once or twice, it’s not a big deal. But if it happens all the time, it should be addressed.
But why is it important? Because other well-performing people will constantly have to fix repetitive issues caused by others, which will decrease their performance and, ultimately, reduce the overall performance of the team. This happens in two ways: first, due to the problem maker, and second, because the people fixing these issues will have their work impacted as well.
Comfort Zone
People only grow when they step out of their comfort zone and try something new. If you’re just fixing bugs, shipping easy features, and avoiding challenges, you’re probably regressing.
Here’s a thought experiment: start a new JavaScript project, leave it untouched for a year, and assume it’s in a “perfect state” when you step away. When you return and try updating any package, it likely won’t build. This reflects what happens to your skills when they remain stagnant.
Familiarity with your daily tech stack is one side of the coin. The other is solving complex problems and navigating unfamiliar environments.
To grow, it’s crucial to take on challenging tasks and stress-test your skills — this “coin” defines your expertise.
This applies universally. Some developers avoid difficult challenges, and while this may work in the short term, they often realize over time how much they’ve regressed. When that happens, even their favorite tools can produce only average results.
Working with those who resist change can be equally challenging. They may repeat ineffective solutions simply because “it’s always been done that way.” Conversely, changing too often can create instability (a topic for the next section).
Refactoring Gurus: The Problem with Constant Change
Imagine having a job where you still receive a paycheck even if you fail at something. Software development is inherently a mix of successes and failures. Code might work perfectly one moment, but once someone touches it, it stops working.
Some people just enjoy typing away and making countless changes to the code. Adding new code is often less risky than modifying existing code — JavaScript developers know this all too well. It’s easy to break things (like a wrong reference to the this keyword), causing unexpected exceptions. But hey, at least now it’s “clean code,” right? It’s not working, bro? Well, at least it’s clean code…
Striving for perfect code doesn’t make sense — such code simply doesn’t exist. Yet, after reading books on design patterns, articles on best practices, or other resources, some developers try to mimic what they’ve seen without understanding the practical context.
First and foremost, code should work. Based on experience, you can mitigate potential problems, but small changes like switching a three-block if statement to a switch rarely make any real difference.
I’m not against refactoring. I’m against touching code purely for the sake of “art.” Bugs introduced during refactoring are among the most frequent and repetitive types of issues.
I’ve discussed more issues with being overly fanatical about clean code and refactoring in the articles Be Careful When Using Design Patterns and Putting Users First in Web Development.
Wrong Work Prioritization
Working step by step is important, but sometimes you need to change the order of tasks. Imagine you’re starting work on a system responsible for registering patients across the whole country. The main bottlenecks will be traffic, stability, and predictability when registering patients.
You can approach it step by step: login, registration, etc. However, the most critical part of the system is the registration block. If you don’t spend enough time preparing a PoC to demonstrate stability, having a great UI or focusing on other aspects of the system will not improve it. It might look nice, but patients will still be waiting four minutes in the registration queue to complete the process.
This example might be too generic, but it highlights the direction. Often during sprints, people add numerous tickets from different features because “we’re Agile,” leaving them unfinished in feature branches or merging them and partially disabling features via feature flags (aligning with Trunk-Based Development). The prioritization of work is really important.
You should start with the most critical parts of a feature (not necessarily from the beginning). For instance, if you’re implementing a calendar widget to show booked appointments, the most important aspect is date management. Instead, people often spend time developing a fancy-looking UI rather than crafting well-defined acceptance criteria or testing scenarios to ensure that everything works as expected.
Of course, you can divide the work to handle it in parallel. However, the approach should prioritize determining whether the core feature is viable first. Once that question is answered, any available developers can focus on crafting the UI, adding animations, performing code refactoring, updating dependencies, and so on.
Ignorance of Team Mindset During Recruitment
Consider a team that has been working together for almost two years. Now, one person — let’s call him Tom Riddle — is leaving the project (thanks for your work, kudos, you were great, good luck, and so on).
Tom had a great character; he acted like a shark in the project. He consistently provided feedback, challenged ideas when necessary, took on many responsibilities, and even tried to lead other team members. He had some authority and influence within the team.
If the recruiter focuses only on the technical requirements — good English, being personable, good communication skills — that’s fine, but it misses an important aspect: the current needs of the team. They need someone like Tom to minimize the impact of his departure (the Shark). This means finding a replacement with a similar skills level and a comparable personality or attitude.
I’ve seen many situations where, instead of hiring someone with a similar character, a completely different personality was introduced. This often becomes a primary source of conflicts within the team. The new member brings a different perspective, pushes for changes — sometimes drastically — and disrupts the existing dynamics.
Don’t get me wrong — change is vital. But if something works well, you should aim to maintain or improve the same level of performance, not diminish it. This is a challenging topic, not a binary 0/1 matter. Anyway, it’s crucial to recognize that matching personalities is just as important as matching hard skills.
Buzzwords, Hypetrain Lying, and Overgeneralization
A developer, inspired by their personal project using a new technology, proposed rewriting an application during a Community of Practice meeting. The suggested benefits were compelling: 40% less JavaScript code to load and a cleaner API. However, due to recent layoffs, no experienced team member was present to challenge the idea or perform a reality check. Trusting benchmarks alone, the team embarked on the rewrite.
Simultaneously, new features had to be delivered. The client was aware of the rewrite but began to complain: Why is this taking so long? Why are there so many issues and bugs?
What followed was a lack of preparation and what I call “technological paralysis.” For the sake of saving 10kB in bundle size, the team spent 3–4 months on a minor rewrite. Without a well-prepared proof of concept, blindly following the hypetrain became a gamble.
When the project dragged on, others were blocked by the ongoing work, the client grew increasingly frustrated, and morale plummeted. Eventually, the rewrite was shipped to production. Yes, the bundle size was 10kB smaller, and there was less boilerplate code, but the application was riddled with bugs.
To be clear, replacing technologies or rewriting an application isn’t inherently bad. However, there must be a real reason for such a decision, backed by solid PoCs and extensive implementation-agnostic regression tests (e.g., end-to-end tests) to catch bugs early.
In this case, after three months of work and burning an excessive amount of money, they ended up with just a 10kB reduction in the bundle size (on slow 3G it’s 0.8-1.6s).
Delegating Everything to One Person
Burnout is a real issue, and its first symptoms are often ignored. Recently, it has become an epidemic in the IT industry.
During periods of heavy workloads, the majority of responsibility and the most challenging tasks often fall on the most experienced and skilled team member. Since they usually enjoy their work, the assumption is: “What’s the harm in giving them more?”
However, our brain’s energy is finite each day. When someone exhausts it completely—and dips into reserves for the next day — they wake up feeling drained, almost like a hangover.
It’s far too common to delegate work in a way that causes one person to shoulder the burden. This is a double-edged sword: they might deliver exceptional results in the short term, but over time, they may burn out and ultimately leave the team.
Being a Ticket Monkey and Lack of Proactivity
“I’m doing what I need and nothing more.” This mindset is common, especially among long-time IT professionals. It often stems from the fear that showing initiative will lead to additional responsibilities without extra compensation.
Focusing on your assigned tasks is fine, as long as you do them well. But when teammates need support, proactivity can make a real difference.
Unfortunately, some people adopt the “my work is done, I don’t care” attitude, which leads to missed opportunities for collaboration. A small extra effort can go a long way in creating a positive impact.
The key is balance. While it’s important to protect your well-being and avoid burnout, avoiding responsibility altogether isn’t the solution. Step up when needed, but set boundaries to ensure a healthy approach for yourself.
Lack of Authority and Mentorship
Every team needs individuals who uphold standards, ensure quality, and drive the project forward. These people act as quality gatekeepers, ensuring shortcuts are avoided and solutions are crafted with care, efficiency, and user satisfaction in mind. They inspire their teammates and lead by example, fostering a culture of continuous improvement.
Such individuals bring invaluable expertise to the table and often take on a mentorship role, helping others grow. Their leadership is trusted, respected, and essential for a team to thrive.
However, many teams today operate within so-called “flat structures,” where leadership is deliberately obscured or undefined (as in JS).
Often, this happens as a cost-cutting measure. Appointing a clear leader typically comes with higher salary expectations, so companies choose to leave leadership ambiguous. Instead, they rely on vague or implicit metrics to determine who stands out among the developers.
This lack of defined leadership creates significant issues, particularly with decision-making. When conflicting opinions arise, who steps in to resolve them? Without a clearly designated leader, responsibility and accountability become blurred, and progress stalls.
Leadership isn’t optional — it’s fundamental. Without it, teams struggle to maintain quality, handle conflicts, and drive the project in a unified direction. Organizations should recognize that strong, visible leadership is not an expense — it’s an investment in the team’s success (at least in my opinion).
Investment in Code, but Not in Stability
Developers often enjoy experimenting with fancy syntax and reinventing solutions from scratch. But did you know that every additional line of code increases maintenance overhead and adds more things to test? Unfortunately, testing is often an afterthought.
Automation testing is crucial — it reduces the time needed to verify changes and ensures the stability of the application over time. Yet, many teams focus on rapid development while neglecting the importance of testing.
A common scenario is when a system’s complexity grows, leading to an exponential increase in possible paths and edge cases. Without automation, manual testing quickly becomes unmanageable. At first, it might take a single person a day to test a release. With time and increasing complexity, it could take a whole week.
This doesn’t mean everything must be automated, but critical areas should always have test coverage. Automate the base functionality of every feature, leaving only the most challenging edge cases for manual testing. Neglecting the value of good automation can lead to a fragile and unstable product that’s harder to maintain and scale.
Testing coverage should not be a metric of quality. It’s important to understand that tests are necessary, but relying on arbitrary metrics—like assuming 90% coverage equals quality while 40% does not—is counterproductive. This perspective is explored further in the linked article.
Different Kinds of Biases and Human Psychology
Let me list a few biases to illustrate the direction:
- Confirmation Bias: The tendency to seek, interpret, and remember information that aligns with our existing beliefs.
- Anchoring Bias: Over-relying on the first piece of information encountered (the “anchor”) when making decisions.
- Availability Heuristic: Overestimating the likelihood of events based on how easily examples or memories come to mind.
- Framing Effect: Allowing decisions to be influenced by how information is presented rather than by the information itself.
- Dunning-Kruger Effect: When individuals with limited knowledge or ability in a domain overestimate their competence.
There are many more biases, but these examples show how easily our judgment can be distorted. Now, imagine making a decision while unknowingly falling into one of these traps.
Humans are strange creatures. Sometimes I wonder if our decisions are less about rational thought and more like a lottery. Perhaps our brains reshape these choices in a way that shields us from the unsettling truth: maybe what we believe to be deliberate, conscious decisions are far more influenced by hidden biases than we realize.
Lack of Proper Design and Planning
Instead of investing time in planning and evaluating whether certain approaches make sense, we, as developers, often jump straight into coding—because it’s the most exciting part. However, this is a huge mistake.
I discuss more about planning in my article: How to Be Productive as a Software Engineer.
More experienced developers tend to write less code initially. Instead, they dedicate time to analyzing, performing reality checks, and anticipating potential pitfalls before diving into implementation. This deliberate approach reduces risks and helps avoid costly errors later.
I’ve encountered numerous cases where a lack of proper design led to significantly delayed delivery times or the creation of severe bottlenecks down the road. In many instances, it has resulted in technical debt. For example, a poorly planned database design is difficult to rectify, especially when architectural layers are absent, and production data is already in use. Fixing such problems can be both time-intensive and risky.
Although endless planning is counterproductive, taking the time to craft at least a basic plan and iterating on it can make a substantial difference. Engaging with others and seeking diverse perspectives during this phase helps uncover potential red flags early, ensuring the project progresses in the right direction.
Sadly, iteration on how something should work and its design is often overlooked in projects. A complex UI dashboard design? Developers often jump straight into coding! Later, after several components are built, you realize just how much improvement is needed. To avoid this pitfall, I suggest the following approach, which has worked well for me and saved me from major headaches:
- Create an Initial Plan: If the feature is complex or unclear, start by drafting an initial plan outlining how things should connect.
- Iterate and Share: Review and refine the plan at least once. Then, share it with teammates or stakeholders to gather feedback and identify potential gaps or challenges.
This method may or may not work for everyone (as I mentioned, it’s just my way), but I encourage you to give it a try and see the difference for yourself. Planning doesn’t eliminate all issues, but it can significantly improve outcomes and reduce the need for extensive rework later.
Working in an async environment can feel like a double-edged sword. On one hand, it allows everyone to operate in their preferred time zones and work at their own pace as long as deadlines are met. Many async setups also include overlapping time ranges for collaboration, which gives developers the flexibility to structure their day in a way that suits them best. This flexibility is a significant benefit that not everyone fully appreciates until they experience it.
Like everything else, async work comes with its challenges. One of the most frustrating issues is what I call Ghosts — people whose work or input is critical to your progress but seem to vanish when you need them most. Imagine this scenario: you work from 9 AM to 4 PM, while a key team member works from 4 PM to 11 PM. If you need their input or a deliverable to move forward, you might not get it until the next day, blocking your progress for an entire work cycle.
The situation gets even worse with Ghosts who actively avoid accountability. These are the people who manage to do just enough to keep their jobs safe while dodging tasks or responsibilities that require effort or collaboration. When something goes wrong, they disappear, responding only after being tagged multiple times or called out directly. They’re skilled at making themselves scarce during moments of crisis, leaving others to pick up the slack.
While async work environments offer incredible flexibility, they also demand strong communication practices and accountability. Teams need clear protocols for collaboration and tools to minimize blockers, such as:
- Defined Overlap Times: Setting mandatory time slots for collaboration ensures that critical discussions or handoffs can happen without long delays.
- Detailed Documentation: Maintaining a central repository of information reduces dependency on specific individuals for answers.
- Accountability Standards: Establishing team norms for responsiveness and accountability ensures everyone contributes effectively, reducing the impact of Ghosts.
Async work thrives on trust and transparency, and without those, the benefits can quickly turn into inefficiencies and frustration. Ghosts may always exist in some form, but strong team processes can limit their impact.
Wasting Others’ Brain Capacity and Power
Overly complex code can drain mental energy during reviews, analysis, or when attempting to make changes. While complexity is sometimes unavoidable due to the inherent difficulty of a problem (e.g., abstracting algorithmic logic), this doesn’t justify all instances of it. Even when you know the syntax and rules, navigating unnecessarily complicated code can consume significant time.
There are cases where developers add excessive abstraction, often in the name of the “art” of clean code. Simple problems are solved with overly complex solutions, or worse, the solution imposes rigid structures on the rest of the codebase. Naturally, predicting an optimal structure for all code in advance is unrealistic and can slow progress. Still, unnecessary complexity isn’t limited to code alone.
“I’m not against Clean Code. I’m against using it everywhere for the sake of the art. I’ve described this problem deeply in Be careful when using design patterns article.“
Whenever someone creates something overly complex — be it code, processes, algorithms, stacks, or anything else — it forces others to expend significant mental effort to understand and adapt to it.
I recall encountering a particularly unusual setup (unusual from my perspective, though others may see it differently) where everything was mocked locally. Backend communication, among other things, was entirely mocked, with mock data spread across nearly every file (slight exaggeration, but it felt that way).
This setup was a maintenance nightmare: keeping the mocks updated with backend responses was tedious, there was no way to test the application’s interaction with a real backend locally, and the predictable response times of mocks created a “comfort zone” for frontend developers. They were accustomed to consistent response times and statuses due to the mocks, leading to a lack of testing for real-world scenarios like poor internet connections, errors, or race conditions.
The problems didn’t surface until testers uncovered bugs, prompting the team to fix issues by adjusting the mocks yet again. I couldn’t grasp the reasoning behind such a setup. While mocking has its merits — such as enabling frontend development when the backend isn’t ready—mocking the entire system seemed excessive. The justification given was that setting up a real backend environment for local development would be prohibitively expensive.
What baffled me was that no one compared the cost of time wasted on endless iterations and instability to the cost of a real backend setup. No one even tried setting up a real backend once to see the impact. How can you make such assumptions without testing them in reality, conducting benchmarks, or gathering opinions from team members?
The purpose of this chapter is to emphasize that developers often create unnecessarily complex solutions, either by reinventing the wheel or implementing ideas driven by belief rather than evidence. Sadly, these approaches can burden others, consuming significant mental energy and diminishing motivation as they struggle to understand or build upon such solutions.
Observations, Lessons Learned, and Summary
The world is complex, and so is software development. I’ve mentioned only the issues I encounter most frequently, but there are many others that may be more impactful for you and your team.
This article focuses solely on identifying these challenges. Finding solutions for each is a topic that warrants a separate article for every section, which is why I wanted to avoid overwhelming this piece.
According to psychologists, recognizing a problem is the first step toward resolving it. It’s like the process for overcoming alcoholism — until you acknowledge the issue, you can’t fully recover.
Although we’re adults, human psychology is complex. While we may be emotionally mature, our behavior often shifts to align with group dynamics when working with others. The situations I’ve highlighted here reflect just how many challenges exist in collaborative environments.
The key takeaway is to first be aware of the problems, and then focus on finding solutions.
If you’re interested in exploring these topics further, here’s a list of books you might find valuable:
- Atomic Habits by James Clear
- Black Swan by Nassim Nicholas Taleb
- Antifragile by Nassim Nicholas Taleb
- Deep Work by Cal Newport
- The Power of Habit by Charles Duhigg
- The Subtle Art of Not Giving a F*ck by Mark Manson
- Grit: The Power of Passion and Perseverance by Angela Duckworth















