

In the previous article, I outlined the problems accompanying Machine Learning – based (ML) projects and how MLOps can help eliminate them, streamlining the work of the entire team. This time, I will try to explain how the need for MLOps arose and answer the question of why existing project roles may not have all the necessary competencies to fill the gap.
ML systems
Building ML systems is different from developing classical software. The work involves exploring a research problem and then training the model to achieve the intended results. This process is more complex than the development of classical systems, where a team of programmers creates the software based on a set of heuristic rules. The experimental nature of ML projects makes their implementation more complex. The figure below illustrates the main stages of ML system implementation:
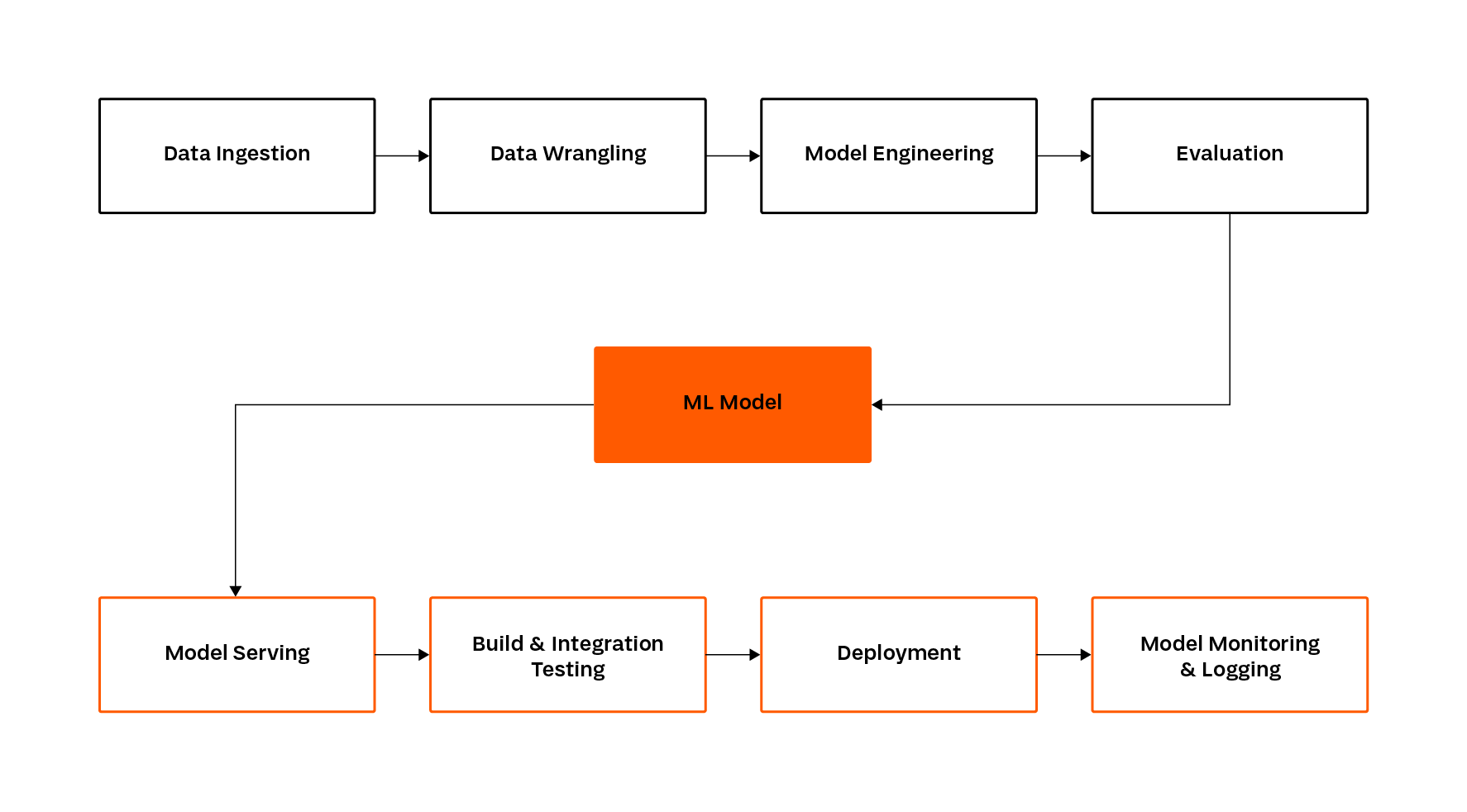
Stages of building systems based on machine learning. Source: own elaboration.
In reality, the implementation of an ML system is a cycle consisting of the above stages, but for the purpose of this article, we will limit the space of consideration to a single iteration. In simple terms, the whole process starts with acquiring data and performing appropriate transformations on it.
The next step is training, which results in a model that meets (or does not meet) the standards assumed by the project. At this stage, the competences needed to perform the necessary actions are limited to the field of Data Science. Problems start only in the next steps.
Each model is implemented with a view to its later use in a real application. At the stage of implementation into the production environment, the amount of knowledge needed to achieve the goal grows dynamically. Issues related to distributed systems, scaling and cloud computing start to appear, and the number of tools that can be used becomes tremendous. The list already seems long, and we haven’t even mentioned things like model registry (version control system) and deployment.
Undoubtedly, this knowledge goes beyond the scope of data engineering and machine learning. Furthermore, the implementation of ML models, in addition to the demanding deployment and maintenance, includes a number of steps that, without proper management, will represent weaknesses. The most common shortcomings are the lack of data/model versioning, testing, and process automation. We will analyse this with an example below.
Versioning of work results
Problem: A team of several engineers, using the most recent data, implemented a new version of a model designed to make predictions based on medical images of skin lesions for early detection of melanoma. The evaluation result is in line with the established standards. The new model is ready to be implemented and replace the previous version.
Previously, the team jointly created a service that serves a given model “rigidly” from a file based on a REST API. Replacing the version involves updating the source code of the underlying application.
Conclusions: In the presented scenario, the service was implemented jointly by the data engineering team. The project did not foresee a scenario in which it would be necessary to update the running model, so it was embedded in the system “rigidly”.
Using a model registry and CD (continuous delivery) it would have been possible to make the system dependent on the versions contained within it, thus injecting the model as a dependency from an external source. The use of tools that allow versioning of data engineering outputs is one of the foundations of MLOps.
It might seem that DevOps will be the solution to these weaknesses. It is a methodology that deals with implementing systems, automating, and monitoring. However, the life cycle of the ML model and the process of its implementation are completely different from building classic software to which DevOps responds.
Significant differences in the process of developing ML systems make it necessary to acquire knowledge of machine learning and model building and maintenance in this variant as well.
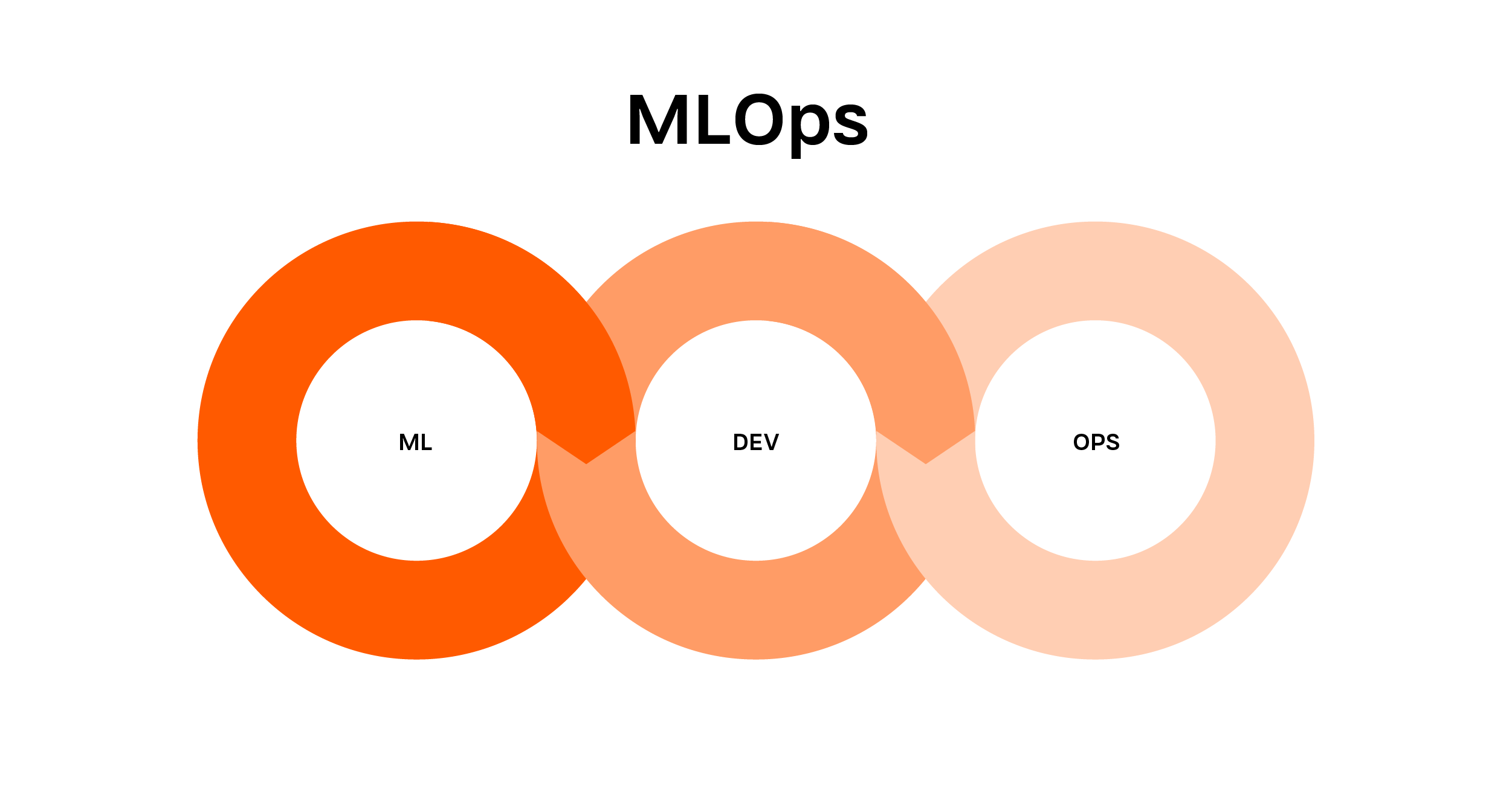
The resulting gap is being sought to be filled by MLOps, which is a combination of competences from fields such as Data Science, ML Engineering, and DevOps. MLOps teams build on the knowledge of implementing machine learning models and inference using them.
In addition, they extend this domain with information from software development and implementation, which allows the model to be packaged into an easily scalable framework such as Kubeflow Pipelines. The final elements that constitute the competencies of MLOps are process automation and monitoring. I have already written about the importance of maintaining ML models in a previous article.
In summary, ML projects pose a number of problems unknown in classic software creation. MLOps as a culture within an organisation tries to answer these problems with good practices and appropriate tools (more).
In the next article, I will introduce the techniques used by MLOps to streamline the process and bring ML systems development to a higher level. Based on specific examples, I will build a model implementation diagram enriched with good practices and dedicated tools to automate the implementation of ML systems.
Next article –How does MLOps support building of ML systems.













