

Through time data lakes evolved while big companies like Netflix or Apple pushed the envelope to its limits and needed to organize table formats better to get information faster. In this blog post, I will explain one of the newest features of modern data lakes – time travel.
What is Data Lake?
First, let’s start with the basics. If you haven’t heard about data lake before, the fastest definition is the following: it is a place that ingests data from multiple sources and makes this data easily accessible at scale to everybody who needs data.
At some level, it can look like this:

but really don’t have to. 
Evolving Data Lake
At the beginning of data lakes, only experienced engineers could access the data because files lived on HDFS, and to get access to them you had to write a custom map-reduce program in Java and run it to get answers to your questions. It wasn’t reliable so engineers at Facebook created Hive to take SQL queries and automatically translate them to map-reduce jobs to run against HDFS.
But Hive was much larger than an only project to translate SQL scripts it introduced Table formats. That increased the speed of queries by organizing data in tables. As time went by, new players emerged to address issues that Hive couldn’t resolve. These players, among others, were Apache Hudi, Apache Iceberg and Delta Lake. The general idea was to create an additional layer with extra capabilities for handling data at scale.
What is time traveling?
One of the most excellent tools that were brought by new table formats was time traveling. Pretty neat, don’t you think? Sadly, this time only your data will travel in time, so put your DeLorean back to the garage. The approach to using time-traveling differs from one format to another, but the rule stays the same. We have chosen a point in time from the past ,and get the state of the data from that time regardless of the current state of the data.
How does it work?
To achieve time traveling, first we have to store every state of a data in a given time. This is possible thanks to snapshots which are stored in the log. Different technologies may have a different name for it, but the mechanism is very similar. We use some parallel computing engine to look through logs and bring up the snapshots we want.
Now that we have a brief idea about time-traveling, let’s check how to use it in the three most popular data lake formats: Delta Lake, Iceberg and Hudi.
Delta Lake
Delta lake is a transactional storage layer designed to work with Apache Spark and take advantage of the cloud.
The project started from collaboration with Apple. During one of SparkSummit, an engineer from the InfoSec team at Apple had a chat with Michael Armbrust. His task was to process data from a network monitor that ingested every TCP and DHCP connection at a company, which results in trillions of records a day.
He wanted to use spark for processing, but spark alone wasn’t enough to handle this volume of data. So that’s how delta lake was born.
Delta lake started as a scalable transaction log. Collection of the parquet files and records of metadata that gives scalability and atomicity. Delta transaction log is written in a way that can be processed by Spark. Scalable Transactions to the entire system to managing and improving the quality of data in a data lake.
Delta Lake offers time traveling as part of Databricks Delta lake, this feature versions data stored in a data lake and lets you access any historical version of data.
Simple example
Accessing historical data can be done in two different ways:
Timestamp
df = spark.read
.format("delta")
.option("timestampAsOf", "2019-01-01")
.load("/path/to/my/table")
SELECT count(*) FROM my_table TIMESTAMP AS OF "2019-01-01"
SELECT count(*) FROM my_table TIMESTAMP AS OF date_sub(current_date(), 1)
SELECT count(*) FROM my_table TIMESTAMP AS OF "2019-01-01 01:30:00.000"
Version number
df = spark.read
.format("delta")
.option("versionAsOf", "5238")
.load("/path/to/my/table")
df = spark.read
.format("delta")
.load("/path/to/my/table@v5238")
SELECT count(*) FROM my_table VERSION AS OF 5238
SELECT count(*) FROM my_table@v5238
SELECT count(*) FROM delta.`/path/to/my/table@v5238
Apache Iceberg
Iceberg is different from Delta and Hudi because it is not bound to any execution engine and it is a universal table format. Therefore, it could be used by streaming service of choice. It has its origins at Netflix.
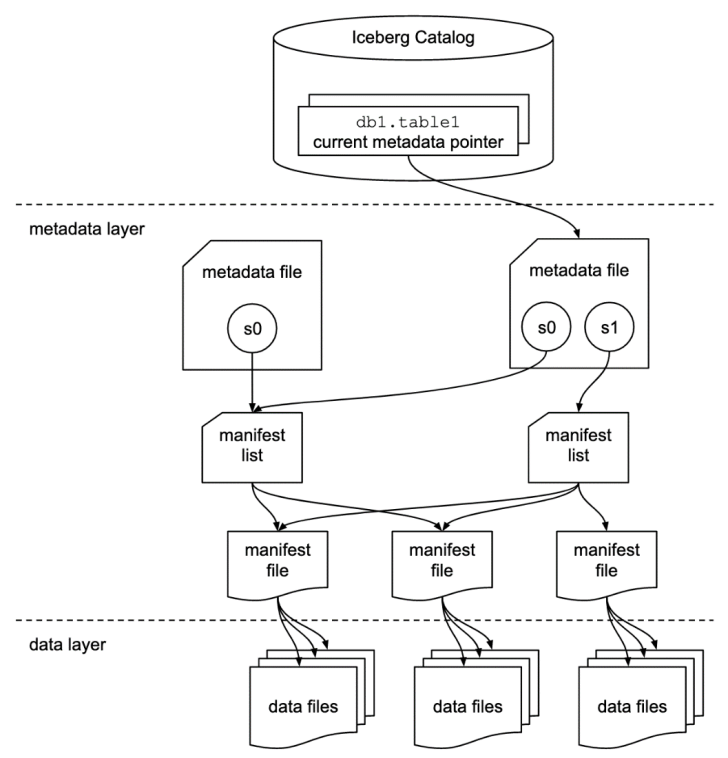
Here is a list of terms used in Iceberg to structure data in this format:
- Snapshot – state of a table at some time
Each snapshot lists all of the data files that make up the table’s contents at the time of the snapshot.
- A manifest list – metadata file that lists the manifests which make up a table snapshot
Each manifest file in the manifest list is stored with information about its contents, like partition value ranges to speed up metadata operations.
- A manifest file – metadata file that lists a subset of data files which make up a snapshot
Each data file in a manifest is stored with a partition tuple, column-level stats and summary information used to prune splits during scan planning.
For a more detailed explanation about the architecture of Apache Iceberg, check out this blog post by Jason Hughes from the Dremio team:
https://www.dremio.com/apache-iceberg-an-architectural-look-under-the-covers/
Simple example
For consistency in examples, we are still using Apache Spark as an engine. You can have two options to perform time traveling, either with a timestamp or snapshot ID.
Accessing by timestamp
// time travel to October 26, 1986 at 01:21:00
spark.read
.option("as-of-timestamp","499162860000")
.format("iceberg") .load("path/to/table")
Accessing with snapshot ID
// time travel to snapshot with ID 10963874102873L
spark.read
.option("snapshot-id",10963874102873L)
.format("iceberg") .load("path/to/table")
Apache Hudi
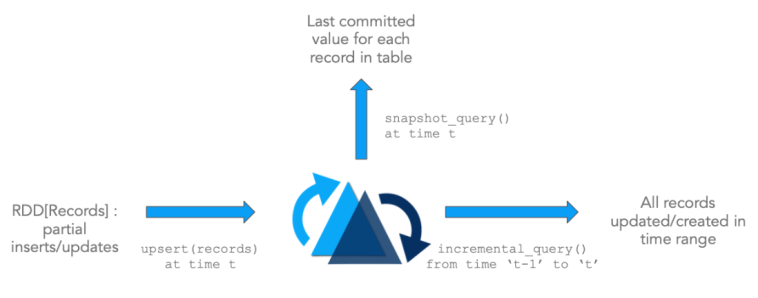
Last but not least, there is Apache Hudi (pronounced ‘hoodie’). It is more stream-oriented than Iceberg or Delta Lake and more like an additional processing layer than only table format to use in the data lake. The main feature of Hudi is to introduce incremental architecture.
Time Travel Query is available only from v0.9.0 in the newest version of Hudi.
You can find more information about Apache Hudi architecture here:
https://cwiki.apache.org/confluence/display/HUDI/Design+And+Architecture
Simple example
Time Travel Query is one of the newest features in Hudi. Before, such an action was possible with a combination of different queries. It supports the time travel nice syntax since the 0.9.0 version. Currently, three-time formats are supported as given below.
spark.read
.format("hudi")
.option("as.of.instant", "20210728141108")
.load(basePath)
spark.read
.format("hudi")
.option("as.of.instant", "2021-07-28 14: 11: 08")
.load(basePath)
// It is equal to "as.of.instant = 2021-07-28 00:00:00"
spark.read
.format("hudi")
.option("as.of.instant", "2021-07-28")
.load(basePath)
Conclusion
Modern technologies for data lakes take effort to provide time-traveling accessible and easy to use. Beyond table formats, there are other solutions supporting this feature like lakefs or hopsfs leveraging the capabilities of the aforementioned technologies.
Time traveling is a valuable feature for everybody that works in pipelines. Data Scientists can access historical models with ease; data engineers can quickly bring channels to a historical state in case of bugs that corrupt the data. It makes the job easier and faster to do everywhere where data evolve and changes frequently.













