

In the survey conducted in 2020, 36% of survey participants said that data scientists spend a quarter of their time deploying ML models. Another 36% of respondents said that the ratio was as high as 1:1. So how to expand the process of deployment of machine learning systems? What should be done so that data engineers can focus fully on their duties? In this publication, I will answer these questions and provide examples of practices used by MLOps to create ML systems more efficiently.
Figure 1 shows the main stages in the process of building machine learning models. This cycle in its raw form has many weaknesses.
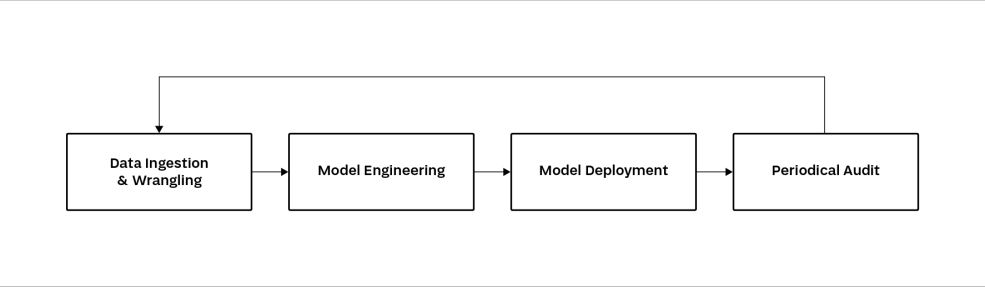
Figure 1 The process of deployment of machine learning systems without MLOps [source: own study].
The main problem is the lack of dedicated mechanisms to deal with boundary situations, since the measure of the quality of a good process is being prepared for any unexpected events. Failure to implement solutions such as a model registry and a dedicated platform for experimentation will make it impossible, for example, to conduct an audit or to restore the system to a previous version in the event of a sudden failure.
Project teams also often choose not to automate repetitive tasks, thus preventing the effective introduction of new members to the team. Work that could be replaced by proper automation has to be done manually, the effects of which can be seen in the results of the survey mentioned at the beginning of this article.
Deployment of MLOps
So how can we overcome these difficulties and expand the process in such a way as to improve work efficiency? MLOps offers the solution! Figure 2 shows the same process as in the example discussed above, but this time it has been expanded to include MLOps practices.
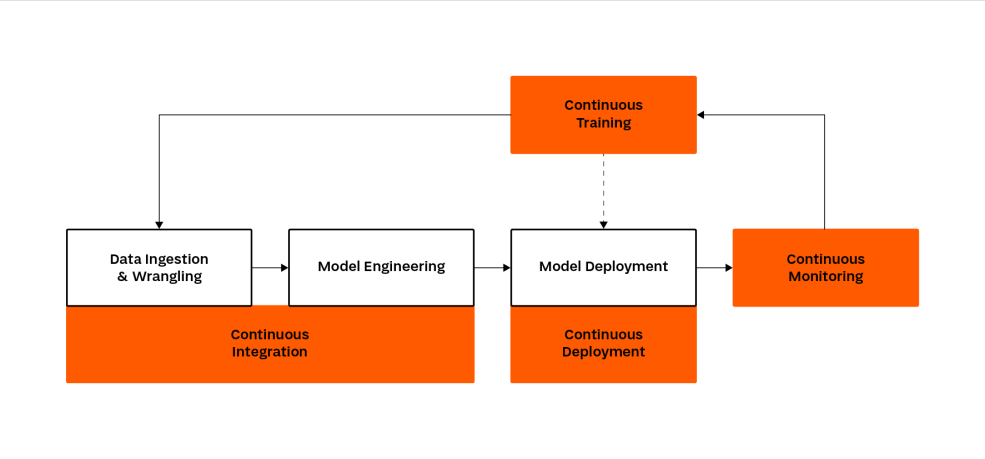
Figure 2 The process of deployment of machine learning systems expanded to include MLOps techniques [source: own study].
Unlike the process shown in Figure 1, the one that includes MLOps practices gives the impression of being duplicated. This is because automation takes place at every stage. In the Figure above, there are the following process improvement practices:
- continuous integration (CI) to validate the analysed data and models;
- continuous deployment (CD) which updates the operating website based on the latest available model version;
- continuous training (CT) which allows the model to be automatically re-trained when necessary;
- continuous monitoring (CM) to ensure control of the quality of the system.
Continuous integration and deployment
The first changes are already visible at the stage of data ingestion and wrangling. It is good practice (especially when analysing sets with a large number of features) to automate testing to examine data quality, data potential or possible correlations. Moreover, when processing sensitive information, validation in terms of regulations in force (e.g. GDPR) may be necessary.
The biggest change, however, occurs at the stage of model deployment. The process using MLOps practices assumes work based on a platform designed for experimentation. Examples of such tools include the following products:
- MLflow — an open-source platform to manage the ML lifecycle; it allows for experimentation, versioning and deployment. Additionally, it has a central model registry.
- Kubeflow — an open-source project dedicated to making deployments of ML systems simple and scalable. In addition to its main goal, the software allows for experimentation, hyperparameter tuning and continuous integration and deployment.
The above tools are not the only solutions on the market, but they are certainly products worth paying attention to. Using a dedicated platform to deploy ML models offers the following benefits:
- ability to reproduce experiments thanks to versioning of data and hyper-parameters;
- work history making it possible to monitor the project progress;
- ease of introducing new employees to the project due to the automation of the process;
- sharing the deliverables in the form of e.g. trained models.
Continuous monitoring and training
The last stage improved by MLOps practices is the monitoring of the production version of the model. Instead of cyclical auditing, dedicated tools can be used to analyse quality in near real-time. This will significantly improve model efficiency. In addition, it will make it possible to avoid risks such as sudden system errors.
Such software can also be used to identify the moment when the predictions made by the model do not comply with the accepted standards and it is necessary to ‘train’ the next version. This can be further combined with a continuous training mechanism that will automatically build and train a new model based on the latest data and then initiate its deployment in the production environment.
As you can see, the introduction of MLOps practices in a project significantly improves the quality of the created software. This article is the third of a five-part series of articles on MLOps. The topics of the remaining two publications will be the monitoring of model efficiency in the production environment and security of ML systems, with examples of potential cyber attacks.
Next article – Monitoring ML models using MLOps.














