

Part 2 – the bad stuff. There are some good things about CDH6 to CDP7 upgrade (which we talked about in part 1 – the good stuff), but there are also some bad things, which Cloudera messed up. Some are minor, some are bizarre, and some are significant. This is what we found:
Sentry to Ranger migration
Although permissions themselves were mostly migrated correctly, you must add a few additional entries to get things working as they should:
- For Hive you must add “storage type” type permissions if you had HBase backed Hive tables. Cloudera documentation have this point, but unfortunately it does not give you a specific string to plug in for Ranger. Use your zookeeper quorum, followed by slash and tables you want to give access to.
- Solr permissions are not migrated at all, you will have to redo all of them.
Sentry to Ranger migration
Yet another point here. The Cloudera upgrade wizard will automatically migrate things to Ranger. This is fine, however if you have many policies (6k+ in our case) the wizard will overwhelm your RDBMS behind Ranger and fail with some SQL errors. If you fail on this step, don’t worry and just resume the upgrade command until you succeed. You will see that the number of “policies failed” will go down with each rerun until you pull through it.
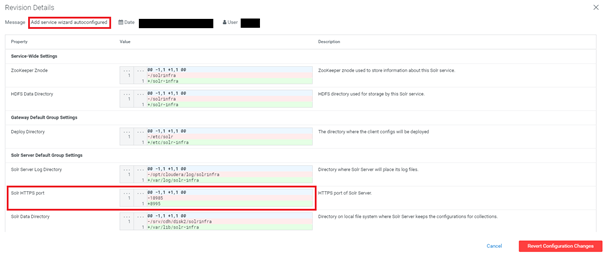
Solr Infra
When you upgrade the CDH, you should deploy a dedicated instance of Solr for Ranger and Atlas. The deployment wizard allows you to choose the port on which Solr Infra will listen. This could be very useful if you have a dedicated Solr cluster with Solr instances everywhere.
Unfortunately, the upgrade process completely ignores your input and reverts to default 8983 (or 8985 for TLS). The solution to this would be to temporary change your regular Solr port number upgrade cluster and then change Solr Infra and revert change on regular Solr.
CDSW + Solr
In configuration for CDSW you have an option to link it with some Solr instance. You can easily do that by selecting a respective radio button in Cloduera Manager. However, if you keep this checked after the upgrade it will cause CDSW to fail at start-up with a strange error.
The error is caused by the inside workings of Cloudera Manager and CDSW CSD. It looks for a service with TYPE Solr (of which you now have 2: Solr and Solr Infra) and when it finds more than one it does not know what to do and refuses to start. Our solution was to simply not link Solr and CDSW.
Python 3 support
Throughout the Cluster, Cloudera distributes a python script (e.g., Into /etc/hadoop/conf/topology.py) that takes a topology.map file and figures out where Cluster nodes are located and how they look from the rack awareness perspective. It is used by services like HDFS, Yarn and Spark.
In CDP, Cloudera changed the topology.map file format, making it more lightweight and simpler. With this change, the python script also had to change.
Unfortunately, the script provided by Cloudera works only in Python 2. This is not a problem if you start your jobs only via spark-submit but will become a problem as soon as you want to run Python 3 script and get a Spark session. If you encounter this issue, you have 3 options:
- As Cloudera for a patched RPM for Cloduera Manager and Cloduera Agents.
- Stop submitting your spark jobs from inside Python3.
- Modify the topology script yourself (there is one join function to fix, one import and one set of parentheses to be added for print at the end).
We chose option 3, as a quick fix, followed by 1.
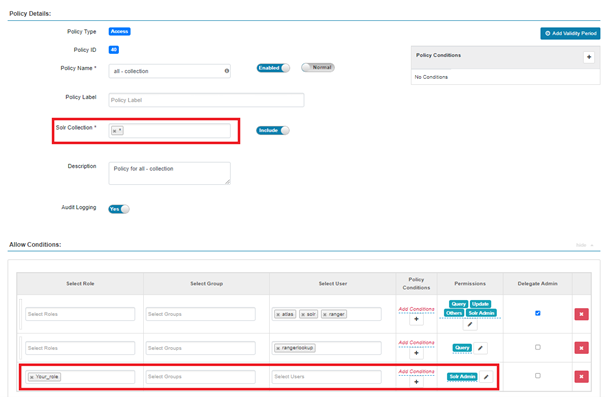
Ranger permissions for Solr Admin
There is a problem with permissions for Solr WebUI. In Ranger you have something called “Solr Admin” that allows you to access WebUI and manage your collections there. However, if you have a few customers who should not touch each other’s collections you have a problem, because you cannot separate collection management in WebUI.
You must grant access to all collections in WebUI or tell your customers that there will be no more WebUI. There is no way to go around it that we know of, so you have to wait for an official patch from Cloudera.
Atlas migration
During the upgrade, you can migrate your linage data from Navigator to Atlas. The process is semiautomated and uses some scripts from Cloudera to convert the data. On the data level it works fine, however it exports a lot of data from Navigator.
This data is temporary stored in /tmp directory and because this is a multipart process, you cannot really change it. Just remember to use a machine with large enough filesystem.
Also, in some circumstances (probably if you have a lot of data, but nobody really knows why) more than one file can be produced. If this happens to you, you should import one file and then import the second one into Atlas.
In the last part, we will look at things that work as they should, but differently than in CDH. Things that you will have to either accept or find a workaround that will make your cluster work just like it worked before. Stay tuned for the ugly part.














