

Part 3 – the ugly stuff. We talked about good things, we talked about bugs, but now is the time to talk about the ugly stuff. Things that “work as designed” but have changed from the previous version in a significant way. These are things you will not get patched, and you have to devise some workaround yourself or accept the different behaviour.
Hive on Tez queue setup
Moving Hive from MR or Spark to Tez is an improvement. However, in the default configuration a Tez job is started in a root.default queue (or a queue you specify in Hive configuration) and then users connect to this particular Hive session.
In our setup it was not acceptable, since we separate each tenant by giving them an equally privileged queue. You can change this behaviour by setting hive.server2.tez.initialize.default.sessions property in Hive on Tez to false and hive.server2.tez.sessions.custom.queue.allowed to true.
It will force you to specify a queue at the start, but also will allow for a resource separation.
Solr schema and config privileges
In Solr secured with Sentry you had privileges for collection (to query and index), but there were also separate privileges for configuration and for schema management. This separation is simply gone in Ranger, and you can grant access only to the whole set (schema + config + collection). There is no workaround that I know of.
Solr document level authorization
Solr 7.4 in CDH6 had a feature that allowed you to secure specific documents inside the Solr collection. We did not use that feature, so we set its respective property to false in solrconfig.xml for our collections.
As it appeared during the upgrade this feature was quietly removed from Solr 8 in CDP and caused our collections to fail right after the upgrade. You should definitely remove all lines pointing to queryDocAuthorization from your config (or figure out a different way to handle your use case, if you are relying on this feature).
Bad config:
<arr name="first-components">
<str>queryDocAuthorization</str>
</arr>
<searchComponent name="queryDocAuthorization" class="org.apache.solr.handler.component.QueryDocAuthorizationComponent" >
<bool name="enabled">false</bool>
<str name="sentryAuthField">sentry_auth</str>
</searchComponent>
Solr built-in configs
Solr has 4 built in configs for you to use (managedTemplate, managedTemplateSecure, schemalessTemplate, schemalessTemplateSecure). These will not be updated during the upgrade (which is probably a good behaviour), but this also means that incompatible features, like document level authorization, will not be removed from them, and any collection created from them will be broken right after the upgrade. If you need a fresh, built in Solr 8 config you can steal one from Solr Infra instance which will be in a default state.
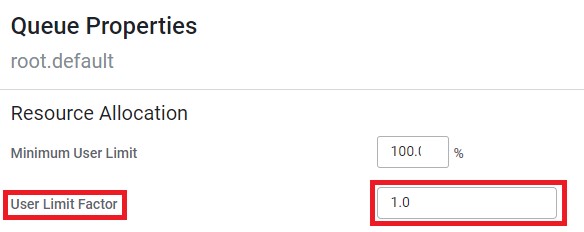
Capacity scheduler – user limit factor
There is a new property for controlling resource allocation in Capacity scheduler. It is called “user limit factor” and it basically says how much of the “minimal resources” one user can get in a certain queue.
This can lead to a strange behaviour when you have many queues, each with relatively small minimal share, and you want to run an application on an empty cluster. Even though there are a lot of free resources you will be restricted to your minimum, unless you change the “user limit factor” to something bigger.
Capacity scheduler – pre-emption
This one was a big one for us. In our setup we have many (15-30) equal tenants on our clusters. In CDH6, the resource division was handled by creating a queue for each tenant with equal weight and letting pre-emption equalize the cluster if we encountered a congestion. This setup allowed us to get a roughly equal resource division over time.
In Capacity scheduler you still have pre-emption, but it pre-empts only to a point of minimal resources. In our case it made up about 2-5% of all cluster resources, so when one tenant started its resource intensive job and the second one wanted a piece of the cluster, it could get only 5%. A situation that is less than ideal.
For this problem we developed our own solution (we called it the Yarn Great Equalizer) that used Yarn API to first query for queues with any applications either submitted or running.
Then we dynamically set the weight of active queues to something much larger than non-active queues (1000 for active, 10 for passive). We did it over and over in 60 second intervals. We used Spring for managing Kerberized REST API calls.
The Scheduler API that changes weights requires admin privileges on Yarn RM. To get the correct Kerberos tickets we integrated the application with CDP by creating a custom CSD for our service. It now runs under the control of Cloudera Manager, gets Yarn configuration from CM (the most important part is the location of both RM) and can be configured via CM.
We also added some additional categories required by our setup (a small weight default queue and a set of super queues with higher weight for our admin tasks).














